
数据集成场景优化——任务编排/限流
资料
Disruptor:
「资料1」建议入门直接看这一个博客深入Disruptor原理: https://ifeve.com/disruptor/
「资料2」这一篇也非常推荐,应用实例: https://tech.meituan.com/2016/11/18/disruptor.html
正文
背景
场景
我们有一个2B的SaaS应用,每个租户下有几万十几万不等的「Item」,我们有一个每天每个租户下都会有上千万次以「itemId」作为参数,来查询这个「Item」需要在查询方应用中该怎么处理的接口。
为了减轻调用方的调用负担,这个接口的入参只是「ItemId」。但在我们接口内部我们会根据「ItemId」拉取能够通过「ItemId」获取到的所有的数据作为实际我们处理过程中所用到信息。举个例子:
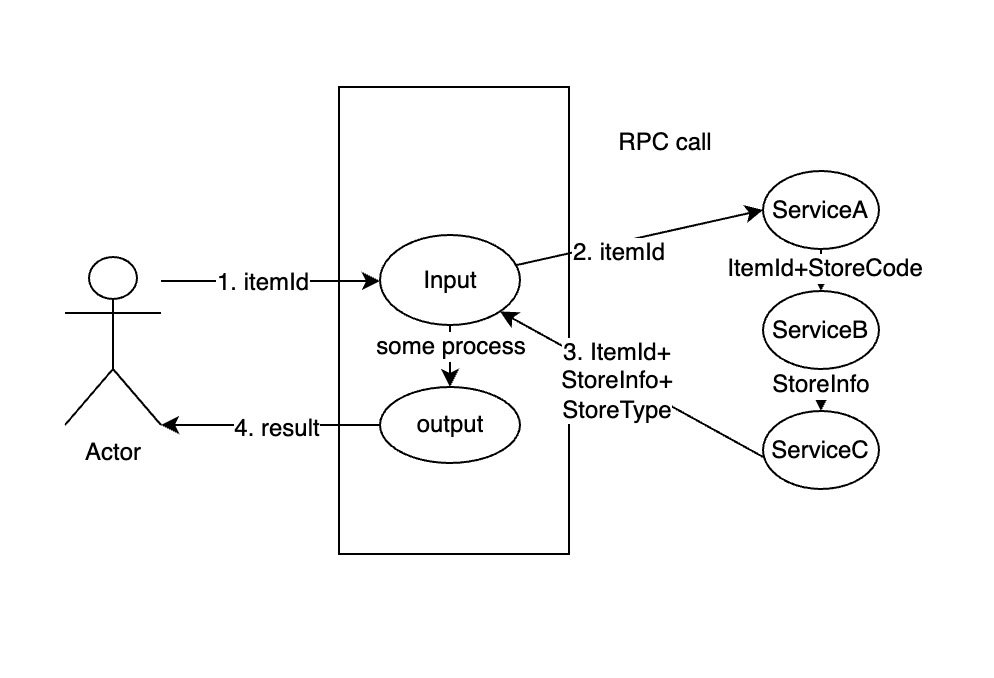
- 调用方使用itemID作为入参请求我们的接口。
- 程序内部通过一连串的请求来拉取使用ItemId可以获取到的参数。
a. 通过itemId获取storeCode的list。
b. 通过storeCode获取StoreInfo。
c. 通过storeCode获取StoreType. - 合并参数并且将参数交给后面的算法处理。
- 结果返回给调用方。
问题
上述的场景其实是一个颇为平常的业务Service的代码流程,不过如果应用在我们的应用中将会遇到了一些问题:
一、RT较高(目标15ms以下):
- 业务请求我们接口,我们的调用ServiceA,B,C 因为都是RPC访问,因此我们接口的整体RT取决于ServiceA,B,C的延迟。尤其是我们的接口调用都集中在某些特定的时间。
- 我们调用其他的接口采用同步阻塞调用的方式,对于整体的IO来说其实没有充分利用计算资源。
二、下游扛不住:
- 因为有某些时刻集会中调用我们的接口,qps非常高。但是Service A,B,C并不能承诺我们这么高的qps。
三、数据集成的复杂性: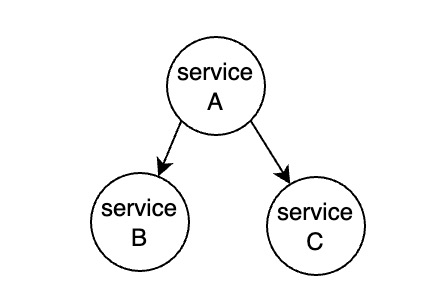
- 任务有依赖关系:比如 Service B和 Service C可以并行,但是他们都依赖于Service A执行完成。如上图。
- 多租户:对于每一个我们应用的租户,都会有自己需要访问的Service D E F和不同的依赖关系。
- 我们依赖的服务全部都是同步接口,采用全异步的编程当然能解决很多问题,但是全域的改造则需要有充足的资源。
思考
首先简单分析一下场景:因为我们应用的客户接入的数据源(也就是Service A,B,C)一般是主数据相关,变化不怎么频繁,通常T-1的时效即可,因此我们大多数情况下可以直接使用离线数据。但是有时候,有些数据源的时效性要求又比较高,比如分钟级别,或直接就必须要实时。因此我们必须要分类处理。将数据源区分为准实时,离线,和实时。
「离线数据」:目前并没有这样的一个数据中间层。因此我们需要使用一个定时运行的离线任务,提前将当前租户下所有itemId能够关联的数据都保存一遍。类似下图所示:
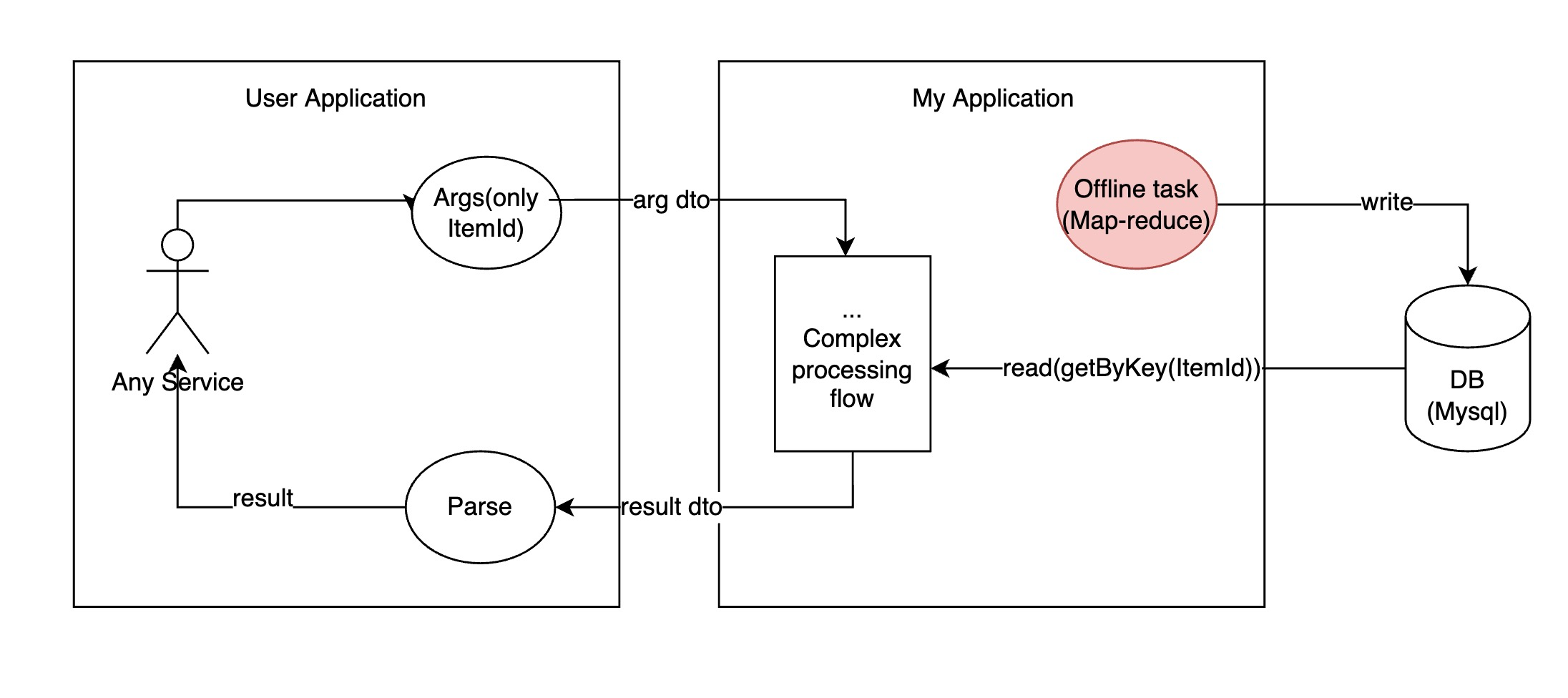
「准实时」:准实时的实现有多种,比如让租户统一告诉我们哪些itemId关联的数据发生了变化。我们再启动离线任务去对这些itemId所关联的信息做异步的更新。
「实时」:如果对一致性要求非常严格,那么我们需要支持实时去访问。
区分数据源要求的时效性的好处显而易见,对于因为离线数据和准实时场景都是去查数据库,而查数据库的延迟和并发就宽松多了。必须实时那部分数据源因为占比的少,因此对平均RT影响不大。当然这只是从性能角度出发,从人效的角度讲,对后续数据源的接入需求来说通过这样的方式能让我们更快定位场景从而更快形成解决方案。
那么一个离线任务如何构建呢?首先这个离线任务执行的快,以达到准实时,那就得并发和非阻塞IO,而且还得考虑数据源之间依赖的问题,那就得想用什么样的数据结构去承载任务?以上述的Service A,B,C我们可以轻松的想到我们可以像运行一个树一样运行,只要中序遍历就好了。 但是现实情况是同一个服务可能有多个依赖。如下图,Service C 依赖 Service A,D。

因此我们其实可以想到最合适的其实是拓扑结构。那么拓扑结构怎么去执行呢?这就需要一个能够支持拓扑任务运行的工具。综合上述的需求,我们采用了Disruptor作为我们的单机任务分发框架。
Disruptor
Disrupoter是一个高性能任务分发框架,本次使用这个框架主要是为了弥补我们正在使用的任务分发框架ScheduleX弹内版不便于处理单机编排流程。我们主要采用了disruptor的after操作来构建拓扑,从而满足我们对io请求先后顺序和并行请求的两个需求(也就是拓扑结构任务的运行)。
Disruptor的整体结构如下:是一个相对简单的机制。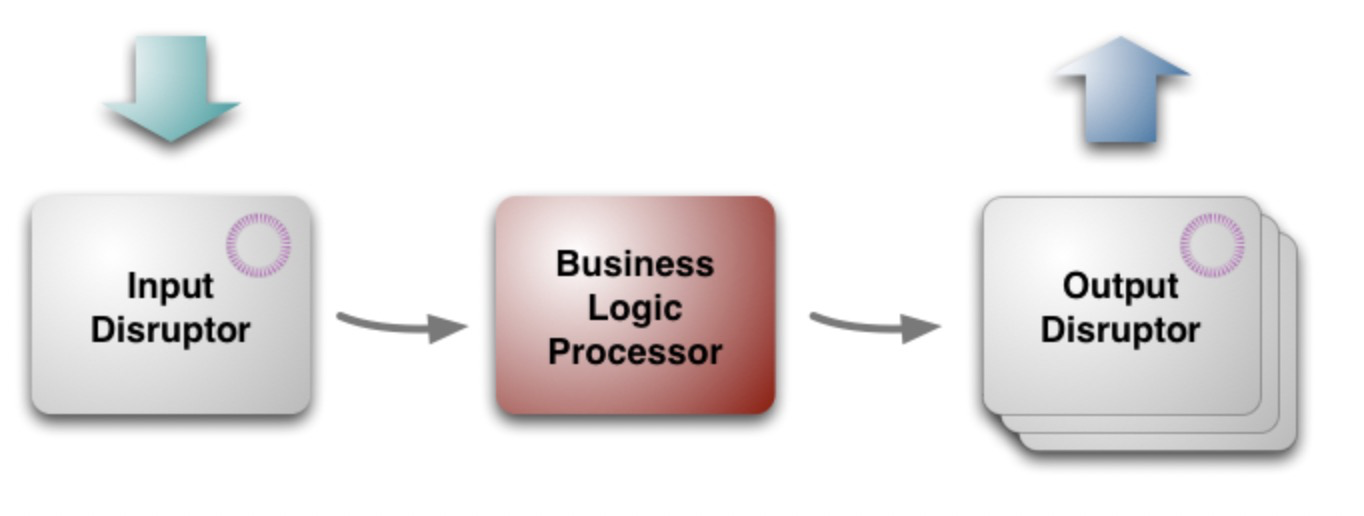
对于我们来说,每个数据源(Service)就一个处理节点。对于树状结构没办法解决的菱形结构如下图: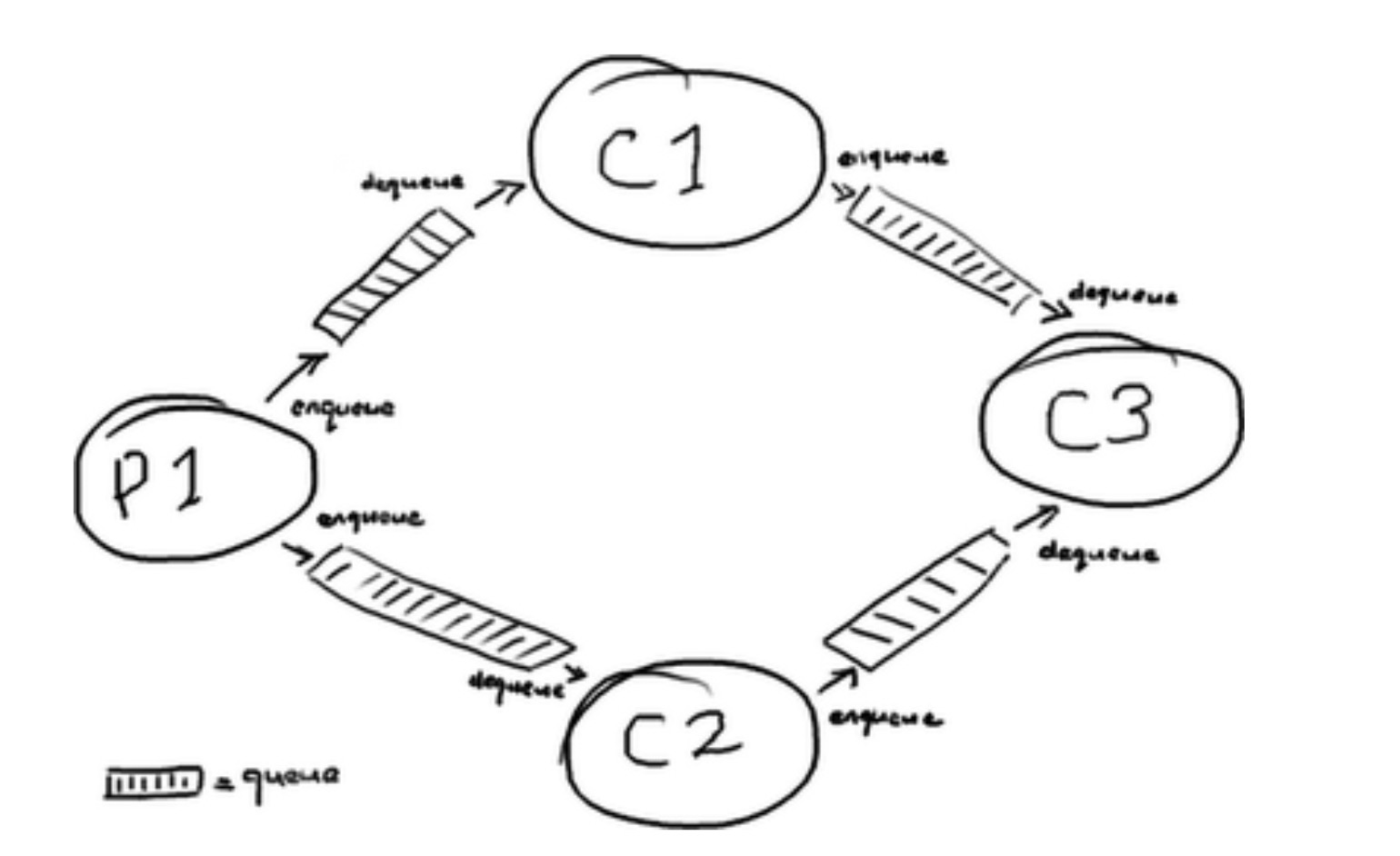
通过ConsumerBarrier 和 处理节点的组合就可以解决这个问题。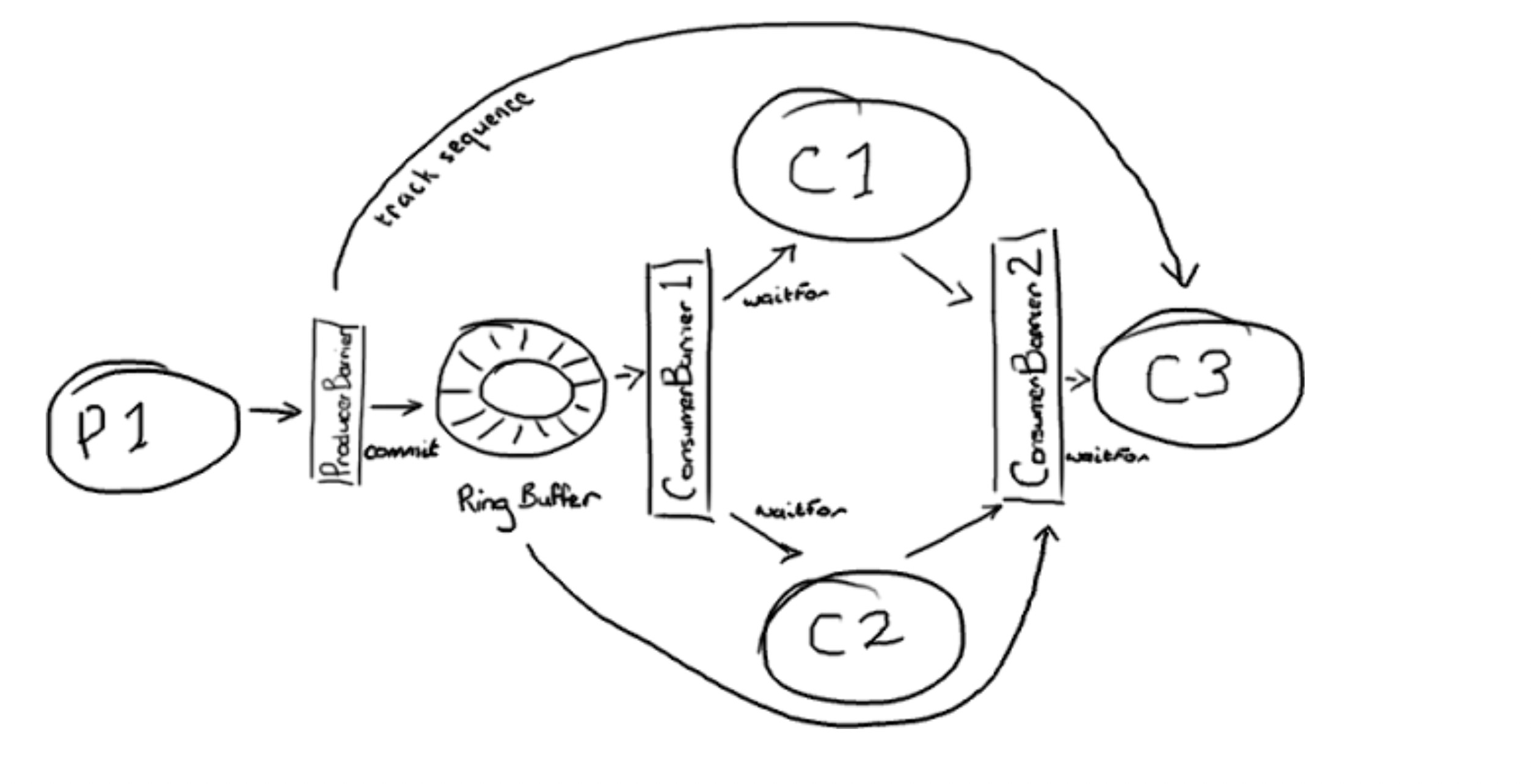
其实上述只是举了个小例子说明disruptor的实现,当然这里有个小细节更能让大家感受到disruptor对各种情况处理的思考。就是disruptor如何实现处理节点的等待(依赖前面的执行结束)。我这里还是举一个官网的例子如下图,详情大家可以自己去研究。
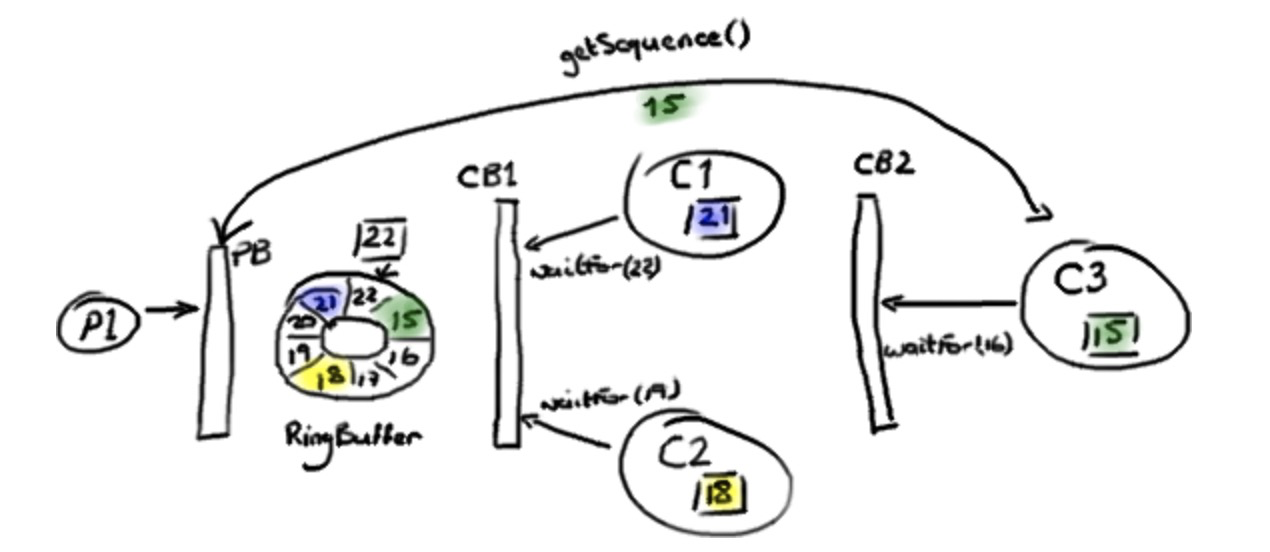
生产者 P1 已经在 Ring Buffer 里写到序号 22 了,消费者 C1 已经访问和处理完了序号 21 之前的所有数据。消费者 C2 处理到了序号 18。消费者 C3,就是依赖其他消费者的那个,才处理到序号 15。生产者 P1 不能继续向 RingBuffer 写入数据了,因为序号 15 占据了我们想要写入序号 23 的数据节点 (Slot)。
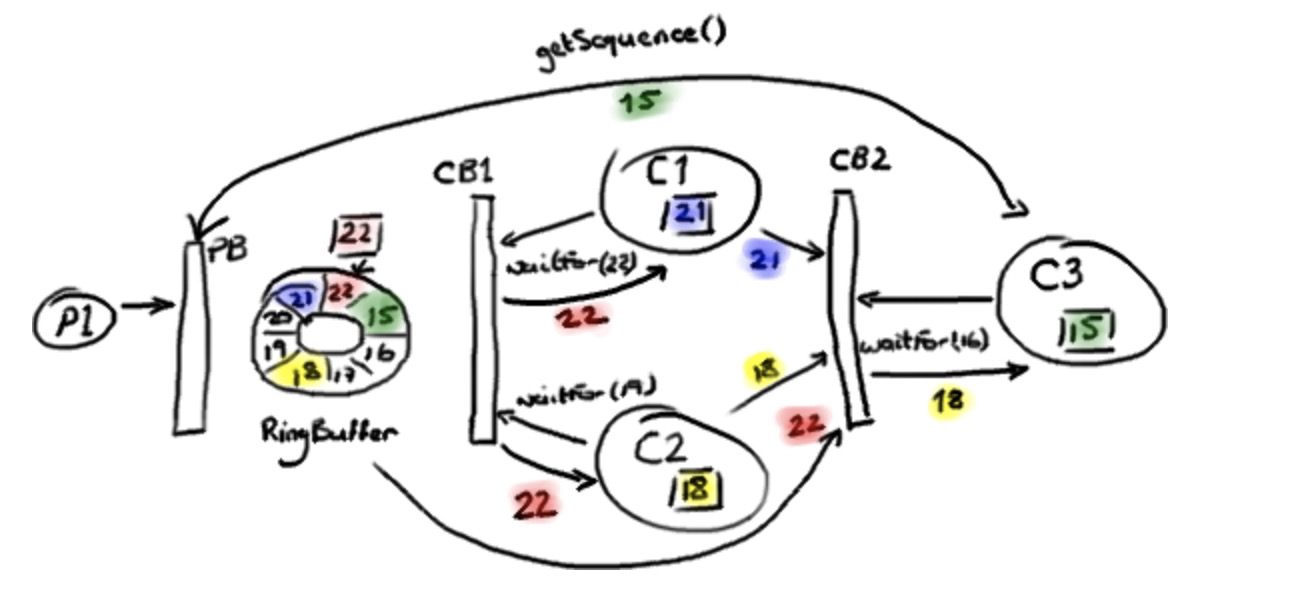
第一个 ConsumerBarrier(CB1)告诉 C1 和 C2 消费者可以去访问序号 22 前面的所有数据,这是 Ring Buffer 中的最大序号。第二个 ConsumerBarrier (CB2) 不但会检查 RingBuffer 的序号,也会检查另外C1和C2已经消费过的序号并且返回它们之间的最小值。因此,三号消费者被告知可以访问 Ring Buffer 里序号 18 前面的数据。
注意这些消费者还是直接从 Ring Buffer 拿数据节点——并不是由 C1 和 C2 消费者把数据节点从 Ring Buffer 里取出再传递给 C3 消费者的。作为替代的是,由第二个 ConsumerBarrier 告诉 C3 消费者,在 RingBuffer 里的哪些节点可以安全的处理。这样的处理能够最大程度减少复制的成本和减少无意义的CPU使用率。
这产生了一个技术性的问题——如果任何数据都来自于 Ring Buffer,那么 C3 消费者如何读到c1, c2处理完成的数据呢?如果 C3 消费者关心的只是先前的消费者是否已经完成它们的工作(例如,把数据复制到别的地方),那么这一切都没有问题—— C3 消费者知道工作已完成就放心了。但是,如果 C3 消费者需要访问先前的消费者的处理结果,它又从哪里去获取呢?
秘密在于把处理结果写入 Ring Buffer 数据节点 (Entry) 本身。这样,当 C3 消费者从 Ring Buffer 取出节点时,它已经填充好了 C3 消费者工作需要的所有信息。这里 真正 重要的地方是节点 (Entry) 对象的每一个字段应该只允许一个消费者写入。这可以避免产生并发写入冲突 (write-contention) 减慢了整个处理过程。
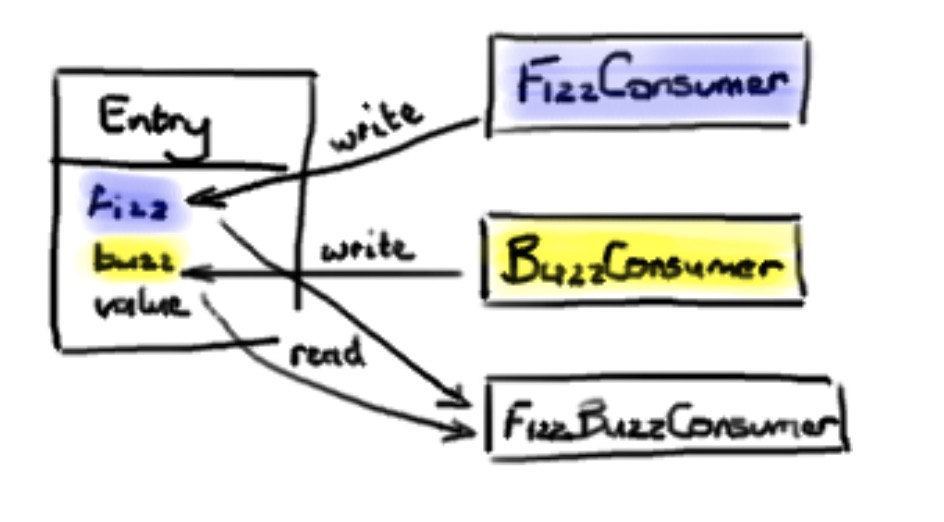
你可以在 DiamondPath1P3CPerfTest:
里看到这个例子—— FizzBuzzEntry 有两个字段:fizz 和 buzz。如果消费者是 Fizz Consumer, 它只写入字段 fizz。如果是 Buzz Consumer, 它只写入字段 buzz。第三个消费者 FizzBuzz,它只去读这两个字段但是不会做写入,因为读没问题,不会引起争用。
这个看起来很复杂,是的,它涉及到更多的内部协调。但是实际上代码实现上很简单,这一切看起来都要比队列实现更复杂。但是这些细节对于我们构建处理node是隐藏的,它们只和 Barrier 对象交互。诀窍在消费者结构里。上文例子中提到的菱形结构可以用下面的方法创建(show code!):
1 | ConsumerBarrier consumerBarrier1 = |
节点流程编排好了之后只需要实现消费者的代码即可。对于我们的SaaS场景也只需要为不同的租户创建不同的编排流程,当然我们做的更进一步,我们使用了可视配置的方式去直接选择依赖数据源。用户无需感知流程的编排过程,只需要写一个实现引入数据源即可。如下图:
限制服务请求流量:
前面我们提到过,我们除了考虑我们的性能之外,还得考虑别人能不能扛得住?也就是限制QPS,这里我们采用了令牌桶算法来针对每一个接入的数据源进行限流,(限制一个节点每秒能够处理的任务数量)。这个原理非常简单就不过多赘述,但是这里也会出现一个问题:
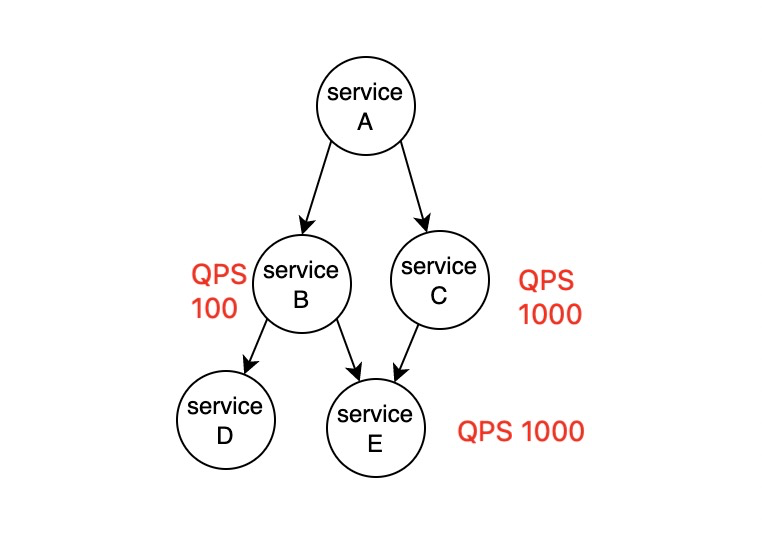
当B节点的QPS成为瓶颈时,其实后面的E和D即使QPS性能更好也无法尽可能充分利用资源。因此这种情况下可能需要对B的性能针对性的进行处理。处理方式很多,根据你的时效一致性来做就行,比如最常用的就是加一个缓存!
离线任务
因为拓扑图的构建对于不同租户来说是不一样的且繁琐的,因此我们需要一种方式去简化这一步。根据传统的离散数学中图论的知识我们知道每一个节点只需要知道他的上一步必须要经过的节点是什么就行了,所以我们就可以复用我们之前接入数据源的流程,只需要在每个节点的配置过程中多加一项上游数据源即可。这样我们对于每个租户就得到了一个数据源的列表,内含每个数据源依赖的数据源。(当然这里我们也需要对回环等问题进行校验)。
那么我们怎么把这个列表和disruptor结合起来变成一个运行态的拓扑任务呢?请见如下代码:
1 | // 处理有上游依赖的节点 |
当然可能结合图会更好理解:
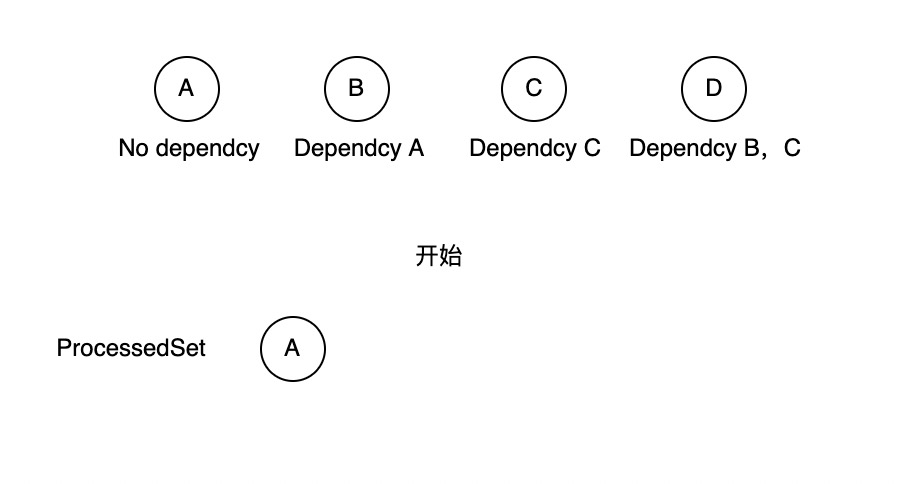
开始我们已处理了一个没有任何依赖的节点A作为我们的开始节点之一。
第一次循环我们就可以处理两个有依赖的节点B和C。因为A已经被处理了
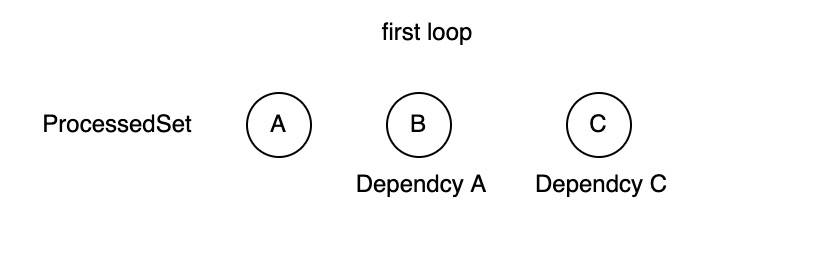
第一次循环中,我们通过循环所有节点,如果当前的节点的依赖的节点都被计算过了,就将其加入后置的处理之中,构建出来的代码就是:
1 | disruptor.after(A 「processedSet」 ).handle(B 「currentHandler」)。 |
而第二次循环则将D节点最终处理掉了
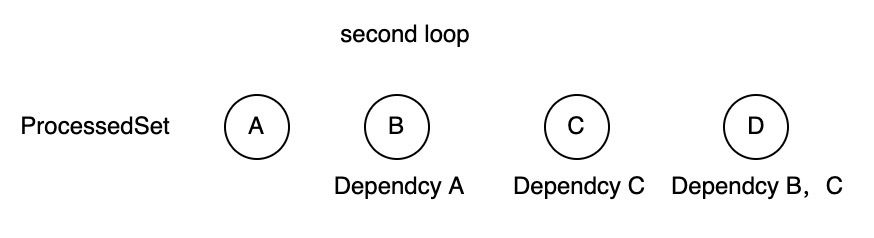
1 | disruptor.after(A, B, C 「processedSet」 ).handle(B 「currentHandler」)。 |
最终进行disruptor的start即可。
过程
讨论
过程中其实我们也是经历了多次讨论,尤其是对于数据的模型。
在数据源中,有一种数据源,是将一份数据 拆成多条数据,就是通过Itemid来查StoreCode。而拿到的ItemId+StoreCode又需要通过一些其他的非批量的节点来处理。如下图:
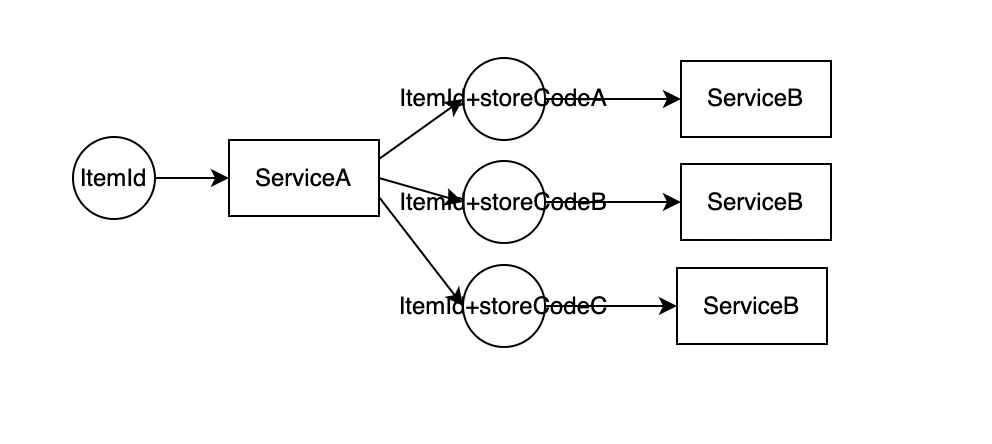
这时候我们对于node的抽象就会出现问题,因为ServiceB不支持批量,因此我们就只能让他循环处理,但是ServiceA却不能,那么我们怎么解决这个问题呢?
我首先对数据定标准,首先对数据来说,我们观测的视角就是数据对维度,比如我们以ItemId的视角去观测数据,得到了一种维度的数据,以StoreCode的视角去观测数据,得到了一种维度的数据,这种我统一把它叫做一维数据。但是这个时候如果我需要ItemId+Store的数据,那么数据的观测维度变成了两个,就叫他二维数据。而维度数据源就是那种对将一维数据转化二维数据的数据源。
其次是数据维度拆分:在我们的概念里面,将数据源分类,分为「维度数据源」,和「维度辅助数据源」。
从实现角度讲维度数据源专门用来将一份数据从一个变成多个,可以理解为从单一视角变成了两个视角,而维度辅助数据源则保持原有维度不变,只是新增了一些同纬度的观测信息,可以理解为看数据的视角变广了,比如通过ItemId拿到ItemInfo的数据源。
在这个前提下我们将Node的实现变为了两种,对这两种Node做不同的编排处理以达到目标。
灰度和对账
灰度我们主要采用diamond灰度开关来去做整体的把控。这部分大家都比较常用,核心讲讲我们对账的经验:
我们还是采用线上的版本和新版本跑出来的结果表来作为对照查看数据是否一致,拓扑任务版本采用了Lindorm+Holo的持久层(这是另一part事,可能可能需要单独开个文章讲hh)天然和odps结合的很好,因此我们利用odps的回流离线表的方式,将线上版本的结果和拓扑版本的结果导入ODPS,再利用MAC数据对账平台https://mac.alibaba-inc.com/odps/ 提供的对账功能花费不到半个人日就完成了对账操作。发现我们的新旧版本的结果数据差异率不到1%,有差别的主要是一些Item的关联信息发生变动。
因此我们认为符合上线标准,准予上线。目前已经切了两个主要行业的租户。线上运行了快半个月了。
结果
最终我们的架构图如下所示:
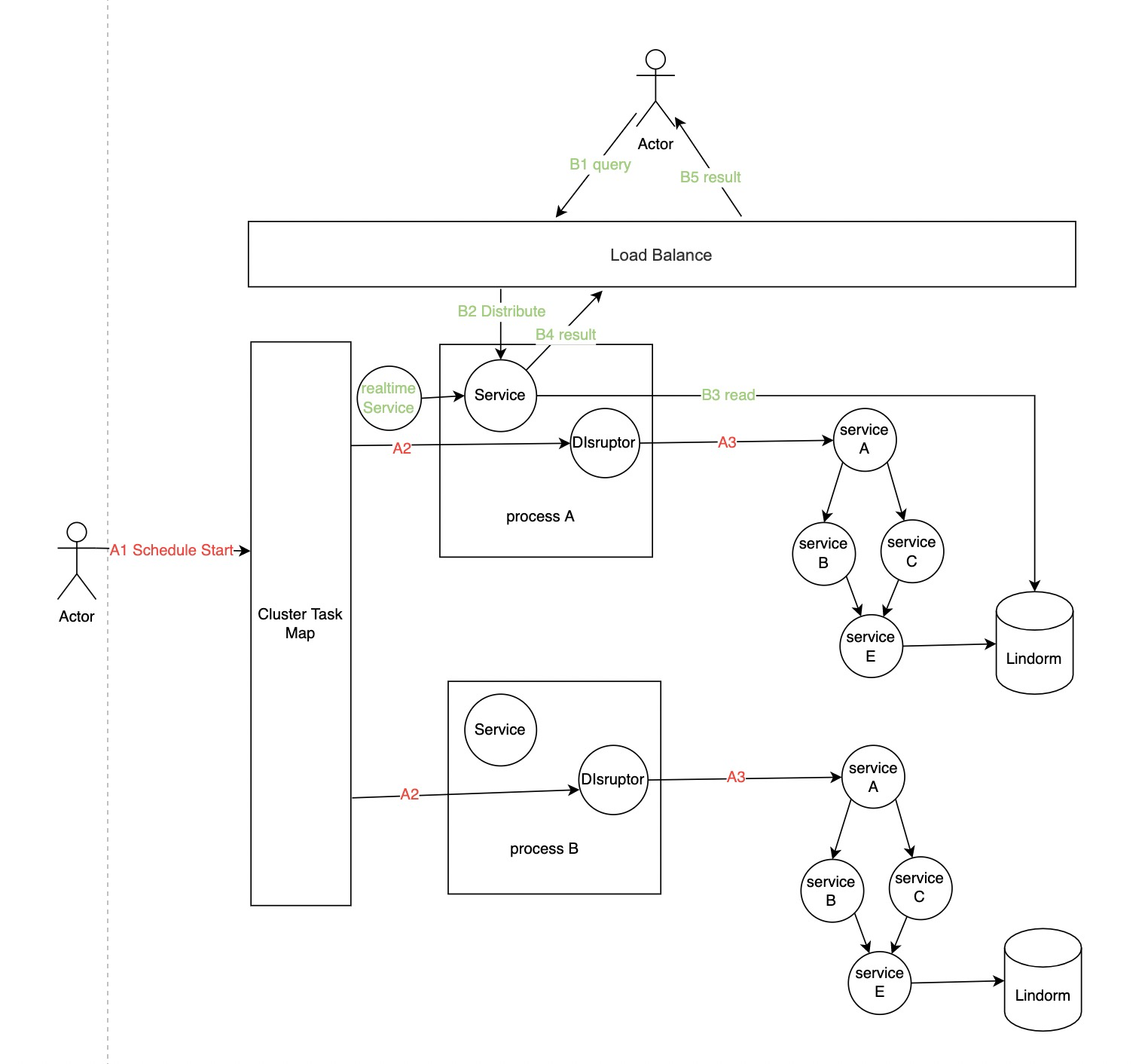
我用绿色B和红色A表示不同的流程:
B流程:正常用户的请求路径,用户的请求除了一些「实时数据源」需要走RPC调用,其余都直接进行查库处理。
A流程:离线任务的主流程,我们会在出解决方案的时候设计日数据版本的概念,一般一个租户一天会运行2到3次。对于「离线数据源」我们无需租户做额外配置。但是对于「准实时数据源」来说,我们会要求租户提供一个能够让我们感知到哪些数据发生了变化的方式。比如MQ消息或调用我们的提供的数据更新接口。
对于行业开发来说,在使用策略开放平台时,在「数据集成阶段」中只需要关心的就是引入一个符合规范的数据源。并且加上简单的配置:
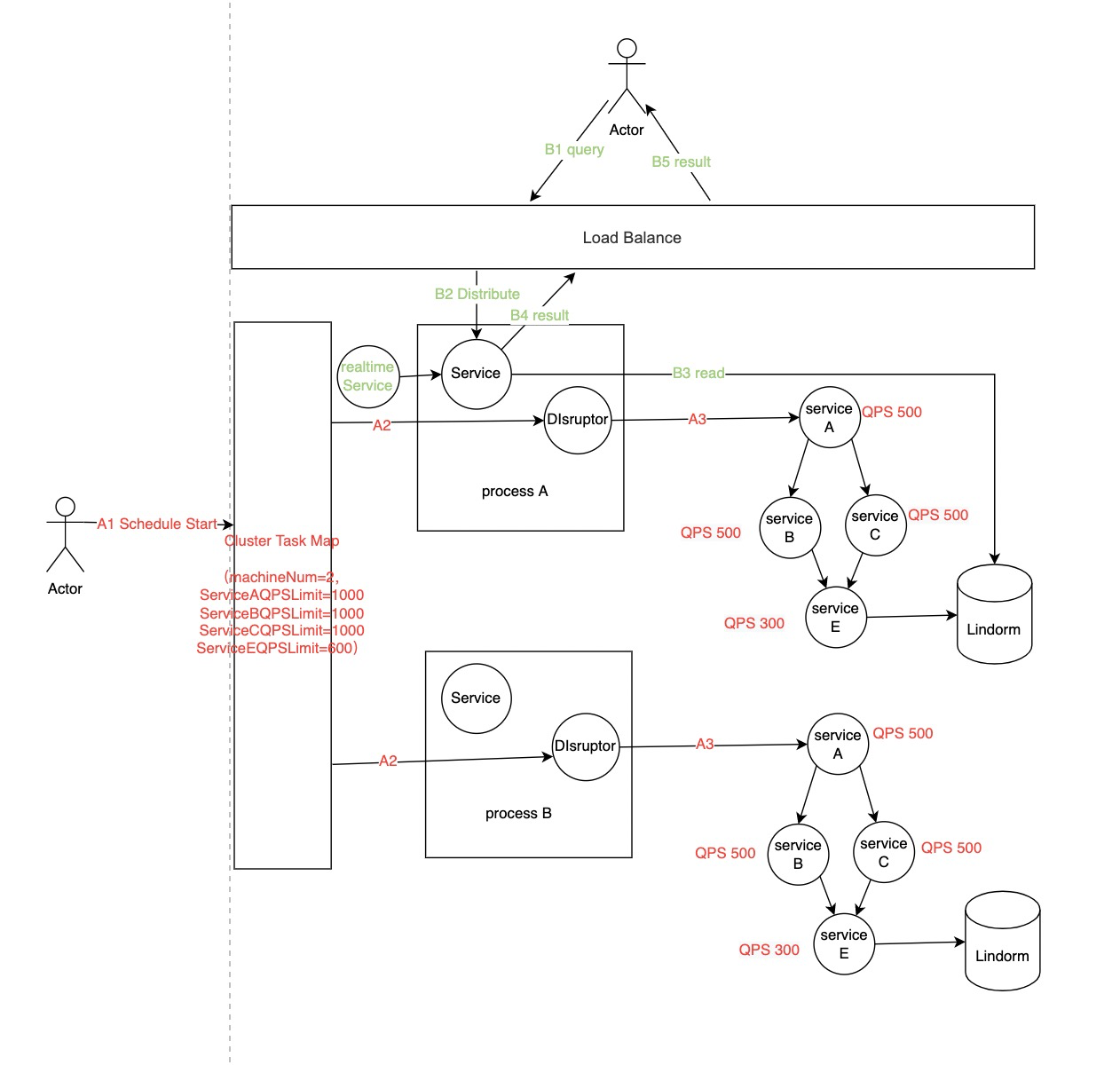
ps:这里加一个小细节,如何将集群的限流转换成对单机数据源的限流呢?
首先我们在出解决方案的时候会预估你需要的机器的数量。
然后会将你配置的QPS上限去除以机器数量,然后每台机器得到的就是这样一个平均过后的机器数量。
最后以每个node得到的QPS作为令牌痛算法的参数。
见下图:
性能测试
我们用直观的离线串行(旧的线上版本)任务和我们的拓扑离线任务在性能上做了一个简单A/B Test:
同等计算资源前提下,数据集成过程性能提升100%。230w左右的离线任务量用原本串行执行的方式大概需要一小时三四十分钟。现在使用以disruptor为主的这套方案只需要不到三四十分钟左右。大大减轻了那些强依赖我们任务结果的下游的处理时间负担(比如我们的大多数任务需要在凌晨几点前跑完用于算法分析)
畅想
其实我们面对的场景是一个相对通用的场景,因此也是我们想要展示给大家看的地方。除了策略中心,我想计划域补货计算等许多产品都在面对我们相似的场景。因此希望提供出来给大家借鉴和指教。
感谢
特别感谢我的师兄灵帝在实现这个的整个过程中对我的支持和讨论,包括后期上线的灰度方案和数据对账,其实都来自于他的经验和沉淀,如果没有这些,我不知道还要踩多少坑。。。
其次感谢今年来实习的眉伯同学,一开始的思路验证工作做的很好。
最后也感谢我们团队的CodeReview机制,让我发现了自己许多代码的问题。
Respect!