
基于Raft协议的NoSQL数据库的设计和实现-DRPC
在分布式领域,必不可少的就是关于远程通信,我们通常把这部分组件抽离出来,并且将其称之为RPC。
- RPC(Remote Procedure Call)远程过程调用,简单的理解是一个节点请求另一个节点提供的服务。
- 本地过程调用:如果需要将本地student对象的age+1,可以实现一个addAge()方法,将student对象传入,对年龄进行更新之后返回即可,本地方法调用的函数体通过函数指针来指定。
- 远程过程调用:上述操作的过程中,如果addAge()这个方法在服务端,执行函数的函数体在远程机器上,如何告诉机器需要调用这个方法呢?
- 首先客户端需要告诉服务器,需要调用的函数,这里函数和进程ID存在一个映射,客户端远程调用时,需要查一下函数,找到对应的ID,然后执行函数的代码。
- 客户端需要把本地参数传给远程函数,本地调用的过程中,直接压栈即可,但是在远程调用过程中不再同一个内存里,无法直接传递函数的参数,因此需要客户端把参数转换成字节流,传给服务端,然后服务端将字节流转换成自身能读取的格式,是一个序列化和反序列化的过程。
- 数据准备好了之后,如何进行传输?网络传输层需要把调用的ID和序列化后的参数传给服务端,然后把计算好的结果序列化传给客户端,因此TCP层即可完成上述过程。
那对一个合格的RPC需要解决以下几个问题:
- 通信协议(序列化和反序列化)
- 动态映射
- API
对于DRPC来说,我们不仅要实现基本功能,更要足够负荷大数据的性能。于是实现方面我们参考了业界通用的Netty作为脚手架工具去在此基础上实现我们自己的RPC。
1. RPC架构设计
Netty是由JBOSS提供的一个java开源框架,现为 Github上的独立项目。Netty提供异步的、事件驱动的网络应用程序框架和工具,用以快速开发高性能、高可靠性的网络服务器和客户端程序。也就是说,Netty 是一个基于NIO的客户、服务器端的编程框架,使用Netty 可以确保你快速和简单的开发出一个网络应用,例如实现了某种协议的客户、服务端应用。Netty相当于简化和流线化了网络应用的编程开发过程,例如:基于TCP和UDP的socket服务开发。DRPC基于Netty构建而成。
1.1 NIO
NIO和BIO不同,是同步非阻塞的,服务器实现模式为一个请求一个线程,但客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
在DRPC中,我们将整个远程调用的过程分为两部分,一部分是多路复用部分,我们称之为IO线程,一部分为worker线程,这部分是为了最大程度利用CPU的多核性能。
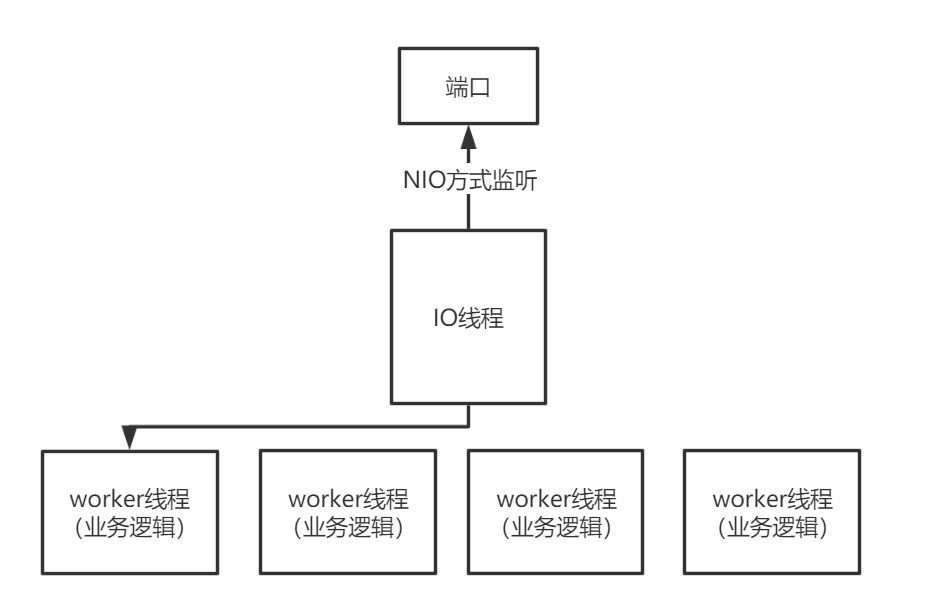
可这样做真的是最大化利用带宽和性能了吗?因为我们使用的是NIO实现标准模式中的Reactor模型标准去构建我们整个RPC,下面先简单介绍一下Reactor,然后再回答这个问题。
1.2 Reactor模型
I/O多路复用可以用作并发事件驱动(event-driven)程序的基础,即整个事件驱动模型是一个状态机,包含了状态(state), 输入事件(input-event), 状态转移(transition), 状态转移即状态到输入事件的一组映射。通过I/O多路复用的技术检测事件的发生,并根据具体的事件(通常为读写),进行不同的操作,即状态转移。
Reactor模式是一种典型的事件驱动的编程模型,Reactor逆置了程序处理的流程,其基本的思想即为Hollywood Principle— 'Don't call us, we'll call you'。
普通的函数处理机制为:调用某函数-> 函数执行, 主程序等待阻塞-> 函数将结果返回给主程序-> 主程序继续执行。
Reactor事件处理机制为:主程序将事件以及对应事件处理的方法在Reactor上进行注册, 如果相应的事件发生,Reactor将会主动调用事件注册的接口,即回调函数. libevent即为封装了epoll并注册相应的事件(I/O读写,时间事件,信号事件)以及回调函数,实现的事件驱动的框架。
使用Reactor模型在工业场景下中有非常明显的优势。
从结构上区分,可以将Reactor模型分为三种模型:
1.2.1 单IO线程,单Worker线程。
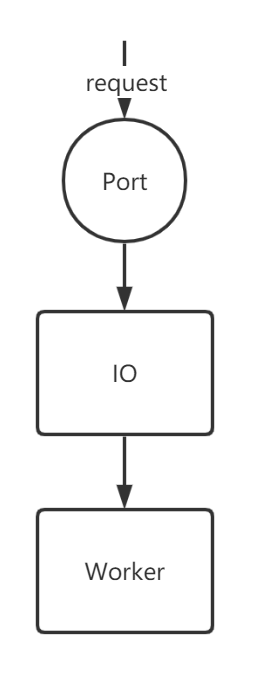
从计算机的角度上讲,在这个流程中,Port是计算机的资源,IO和Woker都是操作系统提供的。从概念上讲,worker线程上注册着真正调用的业务流程,诸如对数据库的读写等。因为worker和IO都是单线程,因此对比传统的BIO并无太大优势。
1.2.2 单IO线程,多Worker线程
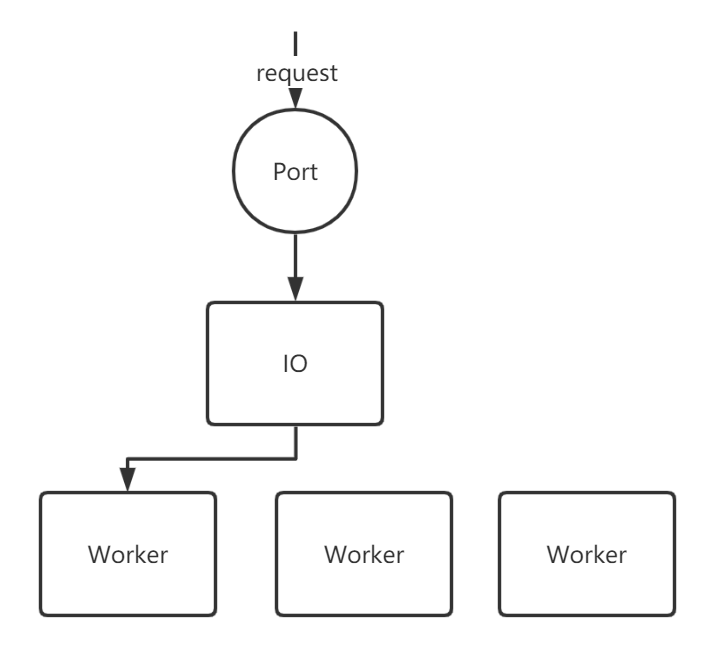
当一个请求通过端口进入IO线程中后,采用多路复用IO的方式,然后将请求分发到Worker线程池中,然后分配worker去调用相应的注册时间。
1.2.3 多IO线程,多Worker线程
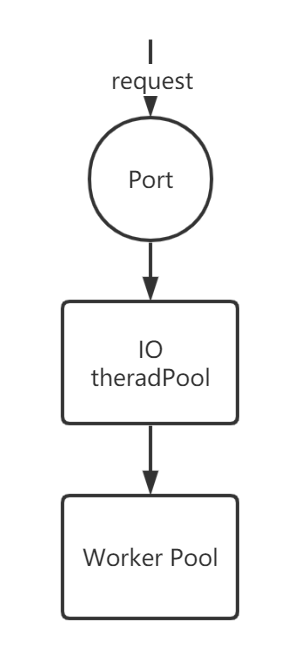
当一个请求进入端口,操作系统使用epoll方式将tcp链接丢入IO线程池,IO读取完毕后再将其丢入Worker线程池。
对于我们DRPC来说,采用了模型二去实现,因为通常来说,部署DIstKV的机器是大内存,低计算性能。实践发现我们再这种机器上,采用模型二的性能最好。一方面是因为线程多代表上下文切换开销大,如果线程过多会导致计算资源的浪费。另一方面IO线程使用单线程能够最大程度利用多路复用的优点。
1.3 编码
DRPC从网络通信在传输层的使用的TCP协议,从应用层面,我们基于Google的Protobuffer构建了自己的协议。
1.3.1 Protobuffer
Protobuffer是Google的语言中立、平台中立、可扩展的,用于序列化结构化数据的序列化框架,类似于XML,但是更小、更快、更简单。您只需定义一次数据的结构化方式,然后就可以使用特殊生成的源代码轻松地在各种数据流和各种语言之间写入和读取结构化数据。
Protobuffer当前支持Java,Python,Objective-C和C ++生成的代码。使用我们新的proto3语言版本,您还可以使用Dart,Go,Ruby和C#,并提供更多语言。
Protobuffer可以为DistKV提供高效便捷的序列化和反序列化的工具支持,并且也和Netty的衔接也很好,可以即写即用,下面介绍一下Protobuffer如何去编码一个简单的Message,从而达到高效快速的目的。
假设您有以下非常简单的消息定义:
1 | message Test1 { |
在应用程序中,创建Test1消息并将a设置为150。然后将消息序列化为输出流。如果您能够检查编码后的消息,则会看到三个字节:
1 | 08 96 01 |
1.3.1.1 Base 128 Varints
要了解您的简Protobuffer编码,您首先需要了解varint。 Varints是一种使用一个或多个字节序列化整数的方法。较小的数字占用较少的字节数。
除了最后一个字节外,varint中的每个字节都设置了最高有效位(msb)–这表明还会有其他字节。每个字节的低7位用于以7位为一组存储数字的二进制补码表示,最低有效组在前。
因此,例如,这里是数字1 –它是一个字节,因此未设置msb:
1 | 0000 0001 |
这是300 :
1 | 1010 1100 0000 0010 |
您如何确定这是300?首先,从每个字节中删除msb,因为这是在告诉我们是否已到达数字的末尾(如您所见,它设置在第一个字节中,因为varint中有多个字节) :
1 | 1010 1100 0000 0010 |
反转两组7位,因为varint存储数字的有效位最低。然后,将它们连接起来以获得最终值:
1 | 000 0010 010 1100 |
除了上面举例的int32,Protobuffer还支持以下的类型,但本论文不再展开相关的讨论了。
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimited | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | groups (deprecated) |
| 4 | End group | groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
下面是我们DRPC所使用的协议:
1 | syntax="proto3"; |
上面展示的是DistKV最基础的请求Message,更多详情可以查看我们发布在github的项目。
1.3 API
对于API来说,我们使用了JAVA的CompletableFuture去封装我们的异步客户端,下面是代码展示:
1 | import org.drpc.Stub; |
服务端的API如下:
1 | import org.drpc.DrpcServer; |
2. 性能优化
除了基本的功能实现外,我们还对RPC可能涉及到的性能和功能性瓶颈做了优化:
2.1 异步驱动
在大多数场景中,我们使用的是同步的请求-响应式的RPC,但这会对客户端性能产生影响,客户端必须等服务端计算完成后返回结果后才可以做其他的事情,但是采用异步则不一样,用户可以将请求返回后要做的事情注册进异步客户端中,当服务器计算完成后,才会调用所注册的事件。而这段时间中,就无需当前线程等待IO的完成而可以有时间去做其他事情。比如我们RPC客户端的异步流程。
1 |
|
首先将我们发送一个请求,获取一个Future
1 | CompletableFuture future1 = service.get(getRequest); |
接着我们向这个future中注册完成后我们需要执行的操作:
1 | if (t == null) { |
这个注册不是一个耗时操作,因此代码会很快执行到下面的other op,不会占用当前线程去处理。除此之外,我们在异步Server上面也做了一些优化,这部分详情可以参考我们的开源代码。
2.2 精简结构
在寻常RPC中,比如阿里巴巴开源的Dobbo中,有许多我们用不到的功能,比如反压,监控,服务注册等,我们目前需要的只是一个点对点的高性能通信框架,因此对于许多扩展,我们选择了不开启,这也为我们提升了不少的性能。
2.3 DistKV和DRPC的结合优化
一开始,我们在使用DRPC时,采用的是单IO线程和多工作线程,但是,DistKV要采用WorkerPool的模型去进行数据操作的必要性有多大,因为从实现角度而言,DistKV所采用的DRPC是基于Netty的。对于Netty来说,他的Worker线程池完全可以复用。比如加一个ThreadLocal的变量,也就是Shard。按照架构设计的话也是没有问题的,而且Netty的Worker线程中也有BlockingQueue,这样对一个Shard的操作也是不会出现冲突的情况,会按照入队的顺序去执行相应的操作。
设计这种结构的最重要的原因是 解耦。复用的方法是一种看似可行的策略,但是这会使得整个DRPC和DistKV会有很大的耦合,不利于DRPC项目的发展。当然这个理由其实不太成立,因为如果对于DistKV来说,RPC只是其中一部分,没有必要为了RPC放弃全部。但是除了RPC部分,我们的分布式架构还包括主从同步,数据迁移,容灾恢复,等部分,这些部分每一个都和shard的结构有着千丝万缕的关系,如果考虑了这一点,就不能更好的考虑另一点,而且每做一步都得考虑这对于远程传输性能的影响,从某种程度上增加了思考的负担。和代码编写的难度。
除此之外, 解耦的另一大好处就是软件升级的成本小,比如我们RPC要做保序的话,完全就可以不考虑其他的限制,只在RPC层面进行考虑。比如如果出现了比Netty性能好的RPC,而线程模型又和Netty不一样,我们就可以无缝切换。但耦合就不行。
当然除了这些问题,耦合的话好处确实很多,比如,性能,因为没有因为没有DistKV-WorkerPool,线程只是在Netty内部管控,这样管理效率更高,因为只有一个线程池可以对他做各种优化。而且线程数量也少于非耦合,减少了上下文切换所需要的开销。