
基于Raft协议的NoSQL数据库的设计和实现-Algorithm和Data struct
1. 整体流程简介
那一个KV对是如何写入我们数据库的呢?
首先,客户端需要从dmeta上先获取全局视图,这是因为我们需要通过一致性hash算法确定我们的key要打入或从哪个partition中获取。
1.1 一致性Hash
一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
但现在一致性hash算法在分布式系统中也得到了广泛应用,研究过memcached缓存数据库的人都知道,memcached服务器端本身不提供分布式cache的一致性,而是由客户端来提供,具体在计算一致性hash时采用如下步骤:
首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。
然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。
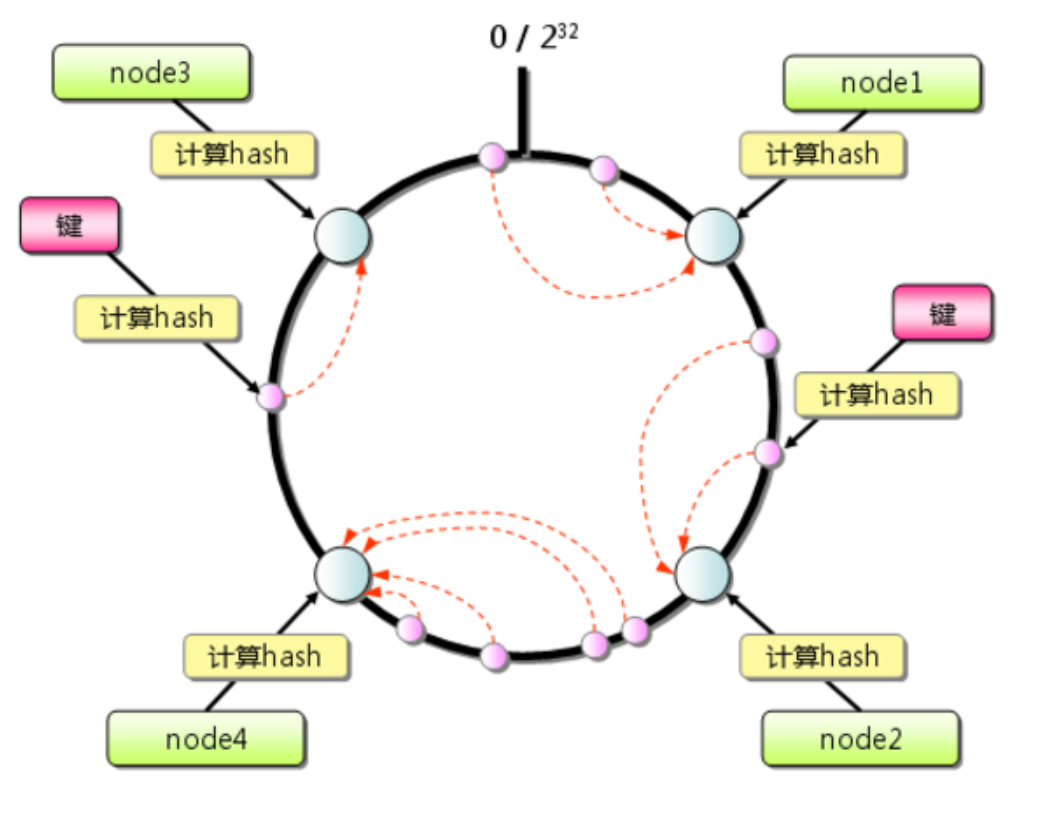
图一 一致性hash 从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在圆(continuum)上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响,如下图所示:
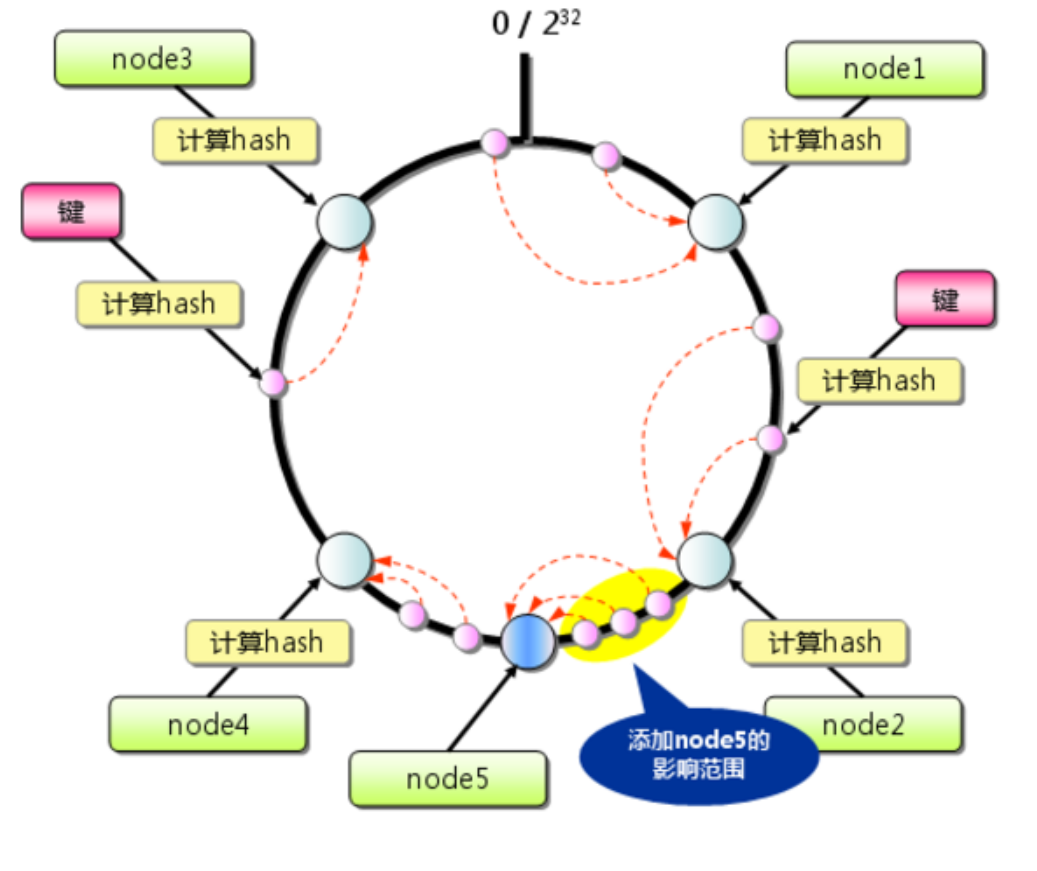
图二 添加节点
1.2 DistKV的Hash流程
一致性Hash的流程比较简单,但对于大数据存储来说,是有些不可接受的。在数据分片情况下,每一个Partition就代表着Hash环上的一个节点,如果采用传统的一致性Hash算法,一旦加入一个新的节点(Partition),那么那当用户get一个key的时候,因为之前这个key可能是被顺时针顺延打了节点4上面,但当新加入一个节点5时key就会打到节点5上,而很明显,这时候节点5并没有这些数据。
不过也不是没有办法去忽略这些影响,我们可以采用rehash,让受影响的那部分重新hash打到新的节点5上。
- 首先所有Partition通过心跳从dmeta中获取全局视图。发现有新节点在hash环中,Partition4根据Partition5的位置判断得出自己需要将一部分数据迁移至Partition5.
- Partition4中的follow节点中的建立对Partition5 leader的连接,并且对内部所有的kv在新的hash环上进行rehash,筛选出需要提交给Partition5的kv。
- Partition4中的follow节点以原子的形式将每一个kv提交给Partition5.
但是很明显,这个过程是一个很耗时的操作,会降低可用性(在kv转移的时候,这些kv是不可用的),并且在现实情况中,运行时横向扩展是不频繁的操作,一般项目构建初期,就会设计好预计所需要的数量级大小,因此为了可用性考虑,我们将这种操作做了进一步优化。
- 当新Partition加入集群时,先不进行任何操作,在dmeta接受其心跳后,会增加一个hash环,和之前的hash环同时保存。
- 提醒所有客户端全局视图有更新,客户端拉取最新的全局视图。
- 客户端遍历同时使用多个hash环运行一致性hash算法,如果得到的结果不一致,就向两个不同的partition同时发起请求。如果这个请求是写请求,则只需要向最新的hash环提交。
这种方式是我们通过实践观察得出,大多数用户其实没有运行时扩容的需求,并且一般运行时更需要可用性,对于用户来说,延迟因为是并行执行,因此也不会出现过大的增幅,不过我们也未在更大数据量和并发量上面进行测试,但预计可以接受。
2. 单机存储引擎
在数据库领域,一般性能优化一方面在于分布式架构,另一方面就在于单机存储引擎,我们目前在使用的就是JDK所提供的ConcurrentSkipListMap,虽然能够提供了排序的能力(为支持大数据表做支撑),但是明显对于一般场景下,这种其实是没有必要的,因此我们也提供了一个高效的hashMap实现,这种专用于不需要table服务,但能很明显提高性能。
2.1 表结构的支持
这里我们参考的是TIDB对Table的实现,详细可以看引用页TIDB的论文,首先假设我们有这样一个表的定义:
1 | CREATE TABLE User { |
SQL 和 KV 结构之间存在巨大的区别,那么如何能够方便高效地进行映射,就成为一个很重要的问题。一个好的映射方案必须有利于对数据操作的需求。那么我们先看一下对数据的操作有哪些需求,分别有哪些特点。
对于一个 Table 来说,需要存储的数据包括三部分:
- 表的元信息
- Table 中的 Row
- 索引数据
表的元信息可以通过专门的冗余数据结构实现,这里不过多展开,对于 Row,可以选择行存或者列存,这两种各有优缺点。我们采用的是行存储的方式。
分析完需要存储的数据的特点,我们再看看对这些数据的操作需求,主要考虑 Insert/Update/Delete/Select 这四种语句。
对于 Insert 语句,需要将 Row 写入 KV,并且建立好索引数据。
对于 Update 语句,需要将 Row 更新的同时,更新索引数据(如果有必要)。
对于 Delete 语句,需要在删除 Row 的同时,将索引也删除。
上面三个语句处理起来都很简单。对于 Select 语句,情况会复杂一些。首先我们需要能够简单快速地读取一行数据,所以每个 Row 需要有一个 ID (显示或隐式的 ID)。其次可能会读取连续多行数据,比如 Select * from user;。最后还有通过索引读取数据的需求,对索引的使用可能是点查或者是范围查询。查询的时候有两种模式,一种是点查,比如通过 Primary Key 或者 Unique Key 的等值条件进行查询,如 select name from user where id=1; ,这种需要通过索引快速定位到某一行数据;另一种是 Range 查询,如 select name from user where age > 30 and age < 35;,这个时候需要通过idxAge索引查询 age 在 30 和 35 之间的那些数据。Index 还分为 Unique Index 和 非 Unique Index,这两种都需要支持。
大致的需求已经分析完了,因为我们有一个Partition内有序的分布式 Key-Value 引擎。这一点重要,可以帮助我们解决不少问题。比如对于快速获取一行数据,假设我们能够构造出某一个或者某几个 Key,定位到这一行,我们就能利用Store Server提供的 Seek 方法快速定位到这一行数据所在位置。再比如对于扫描全表的需求,如果能够映射为一个 Key 的 Range,从 StartKey 扫描到 EndKey,那么就可以简单的通过这种方式获得全表数据。操作 Index 数据也是类似的思路。
DistKV 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID(如果表有整数型的 Primary Key,那么会用 Primary Key 的值当做 RowID),其中 TableID 在整个集群内唯一,IndexID/RowID 在表内唯一,这些 ID 都是 int64 类型。
每行数据按照如下规则进行编码成 Key-Value pair:
1 | Key: tablePrefix{tableID}_recordPrefixSep{rowID} |
其中 Key 的 tablePrefix/recordPrefixSep 都是特定的字符串常量,用于在 KV 空间内区分其他数据。
对于 Index 数据,会按照如下规则编码成 Key-Value pair:
1 | Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue |
Index 数据还需要考虑 Unique Index 和非 Unique Index 两种情况,对于 Unique Index,可以按照上述编码规则。但是对于非 Unique Index,通过这种编码并不能构造出唯一的 Key,因为同一个 Index 的 tablePrefix{tableID}_indexPrefixSep{indexID} 都一样,可能有多行数据的 ColumnsValue 是一样的,所以对于非 Unique Index 的编码做了一点调整:
1 | Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID |
这样能够对索引中的每行数据构造出唯一的 Key。 注意上述编码规则中的 Key 里面的各种 xxPrefix 都是字符串常量,作用都是区分命名空间,以免不同类型的数据之间相互冲突,定义如下:
1 | var( |
因为我们在Store Server内部的SkipListMap是通过字典序排列的,因此只需要按照我们设定的方式小心写入即可。
2.2 Swiss Map
上述表结构的实现其实是基于有序的存储引擎,但就如同前文所言,其实很多情况下,业务用不到table,那么我们如果采用全局hash的方式写入和读取,就会使得整体性能快上不少。
这里主要参考google的swiss Map来实现,使用到了X86_64CPU所支持的SIMD指令集。
2.2.1 SIMD
SIMD,即Single Instruction, Multiple Data,一条指令操作多个数据.是CPU基本指令集的扩展.主要用于提供fine grain parallelism,即小碎数据的并行操作.比如说图像处理,图像的数据常用的数据类型是RGB565, RGBA8888, YUV422等格式,这些格式的数据特点是一个像素点的一个分量总是用小于等于8bit的数据表示的.如果使用传统的处理器做计算,虽然处理器的寄存器是32位或是64位的,处理这些数据确只能用于他们的低8位,似乎有点浪费.如果把64位寄存器拆成8个8位寄存器就能同时完成8个操作,计算效率提升了8倍.SIMD指令的初衷就是这样的,只不过后来慢慢cover的功能越来越多.
2.2.2 SwissMap概述

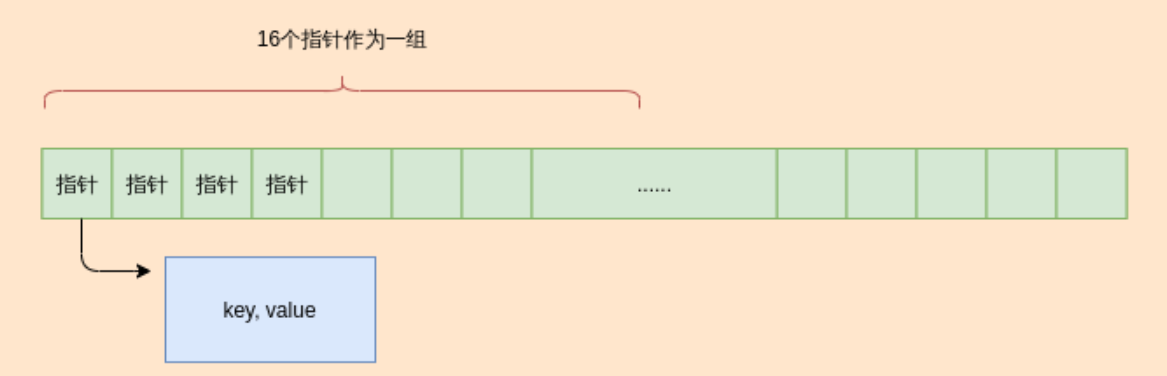
将16个键值对划分为一组,也可以把这个组叫做桶,存放在逻辑连续的线性地址空间内。(哈希函数计算的64位哈希值的前57位)/(哈希表的容量)计算出某个key对应的桶,如果桶内存在空闲或者键值对被删除的槽位,就可以将该键值对存放在这个位置里,否则顺序存放到下一个桶内。每个槽位都有一个字节的元数据与之对应,当元数据为000000的时候,表示该槽位是空的,11111110表示该槽位上的元素被删除了,否则该槽位存在一个元素,其对应的元数据的首位为1,剩下的七位为第二个哈希函数计算出来的值。
2.2.2.1 为什么需要一个字节的元数据
元数据被用来快速检索,可以通过SIMD(单指令多数据)指令通过位运算快速判断组内是否存在空闲元素,或者已经满了, 以及匹配第二个哈希码计算出来的七位元数据相匹配的槽位。16 x 8 = 124bit,能够放入L1缓存,所以是缓存友好的。
2.2.2.2 哈希冲突
哈希表通过空间换时间,只要选择的hash函数足够好,计算出来的哈希值分布均匀,那么某个元素应为哈希冲突,需要存储到下一个桶的情况应该很少。
2.2.2.3查询数据
先通过第一个函数计算出哈希值,找到桶的位置
然而计算第二个哈希函数,找到桶内匹配该哈希值的槽位。找不到就继续从下一个桶找,指导发现一个空的槽位或者被删除的槽位。
找到的槽位对应的索引就是对应键值对指针在指针数组中的索引。然后通过找到的索引值找到key,value值。
2.2.2.4 Resize
当扩容过程中,我们没有必要冻结整个hashmap。假设一个hashmap的容量是64, 某个key扩容前所在桶是第28个桶,那么扩容一倍后对应的桶,可能仍然是28,也可能是92,但就只有这两种情况。在扩容过程中, 可以通过额外查询一次来确保获得值,直到扩容完成。但另一个挑战在于如果使用异步扩容,如何避免完全不用锁呢?因为如果扩容是异步的,必然由另一个线程来完成,那么resize的线程可能和执行插入,查询的线程由不同的CPU来执行,访问不同CPU的缓存。由于缓存不会立即更新到主存,主存的数据也不一定立即更新到另一个缓存,所以不同CPU会读到不一致的数据。但是如果加锁势必影响性能。
2.2.2.4 非堆数据存储
由于Java直接内存分配速度限制,频繁使用Unsafe来分配直接内存是不可取的。所以每次分配相对较大的内存块 Block ,并且使用 BlockPool 来预分配内存。 Block 的大小应该是内存页的倍数,这样做的原因可能有两个,一是内存对齐,二是内存不足时,swap友好。
1) 如何存储定长数据
如果数据长度已知,我们直接可以使用偏移量来定位数据所在位置,并且支持原地更新。
2) 如何存储变长数据

变长数据则需要额外的int类型的元数据来定位变长数据的起始位置和长度。元数据从数组的起始位置开始存,变长数据从数组的结束位置开始存,这样做的好处是我们能够很快的找到当前数组中第n个元素的起始位置。此外,第n-1个元素的起始位置减去1,就是当前元素的结束位置。如果n是第一个元素,那么当前元素的结束位置就是数组的末尾。
3) 内存回收
对于变长元素数据,由于并不总是能原地更新,以及出于效率考虑,我们更新数据的时候总是插入一个新的数据,然后修改对应的指针到指向新的数据。这时候,内存回收就会是一个问题。在这里我们可以考虑使用位图索引来记录被删除的元素,如果删除的元素过多,可以考虑合并block。具体如何合并仍然存在挑战。