
基于Raft协议的NoSQL数据库的设计和实现-Raft
1. Raft的历史
所有共识算法都是由一个基本的问题出发的,就是拜占庭将军问题:拜占庭将军问题是一个协议问,拜占庭帝国军队的将军们必须全体一致的决定是否攻击某一支敌军。问题是这些将军在地理上是分隔开来的,并且将军中存在叛徒。叛徒可以任意行动以达到以下目标:欺骗某些将军采取进攻行动;促成一个不是所有将军都同意的决定,如当将军们不希望进攻时促成进攻行动;或者迷惑某些将军,使他们无法做出决定。如果叛徒达到了这些目的之一,则任何攻击行动的结果都是注定要失败的,只有完全达成一致的努力才能获得胜利。
拜占庭假设是对现实世界的模型化,由于硬件错误、网络拥塞或断开以及遭到恶意攻击,计算机和网络可能出现不可预料的行为。
基于这个问题,Google给出了自己的解法,就是Paxos算法,但这种算法过于复杂且难以实现。然而在真实的云计算环境下,“欺骗将军”这一过程是几乎是不太可能实现的,因此为了简化Paxos算法,斯坦福大学提出了一种新的分布式一致性算法Raft算法,这种算法巧妙且易于理解的解决了这个问题。
2. 算法过程
在Raft中,任何时候一个服务器可以扮演下面角色之一:
- Leader: 处理所有客户端交互,日志复制等,一般一次只有一个Leader。
- Follower: 类似选民,完全被动。
- Candidate候选人: 类似Proposer律师,可以被选为一个新的领导人。
Raft阶段分为两个,首先是选举过程,然后在选举出来的领导人带领进行正常操作,比如日志复制等。下面用图示展示这个过程:
任何一个服务器都可以成为一个候选者Candidate,它向其他服务器Follower发出要求选举自己的请求:
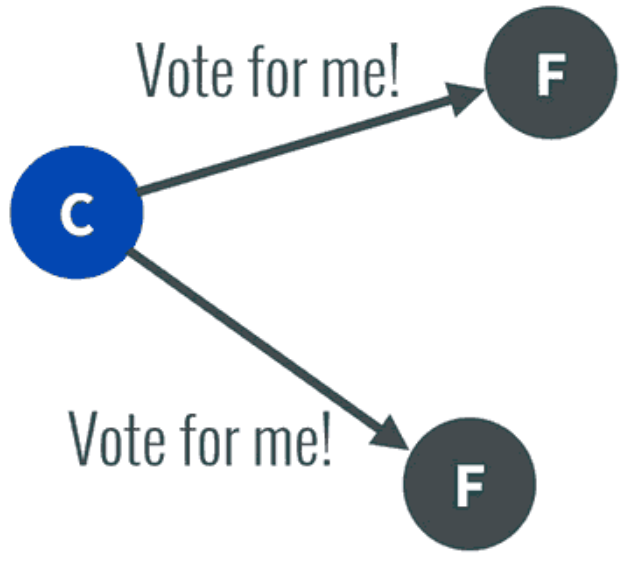
图一 Raft选举 1 - 其他服务器同意了,发出OK。
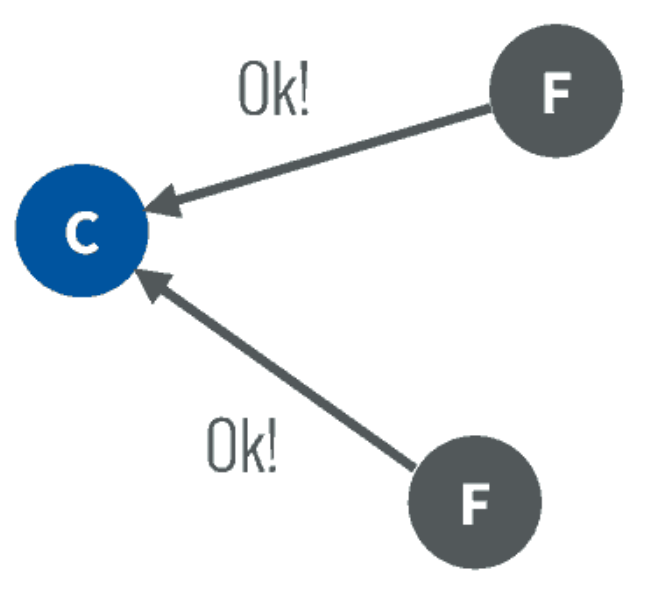
图二 Raft选举 2 注意如果在这个过程中,有一个Follower宕机,没有收到请求选举的要求,因此候选者可以自己选自己,只要达到N/2 + 1 的大多数票,候选人还是可以成为Leader的
成为leader后,leader节点就会接受外部请求从而改变状态机的状态,并且将日志复制到其他Follower节点上。
- 以后通过心跳来监控节点状态和作为日志复制的通知。
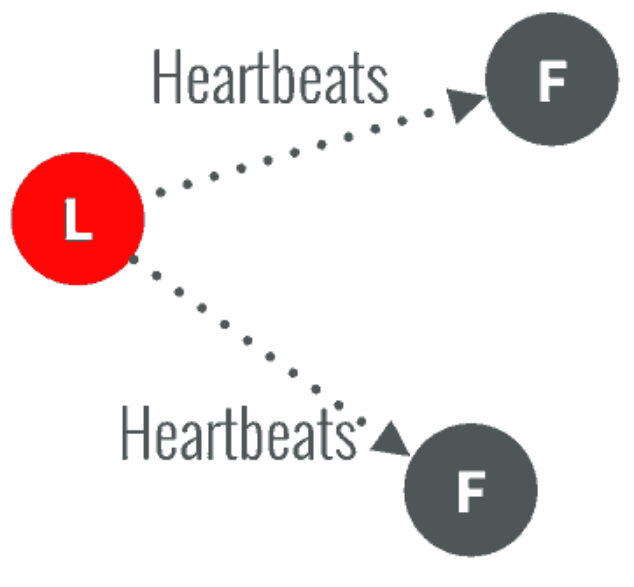
图三 Raft选举 3 如果一旦这个Leader当机崩溃了,那么Follower中有一个成为候选者,发出邀票选举。
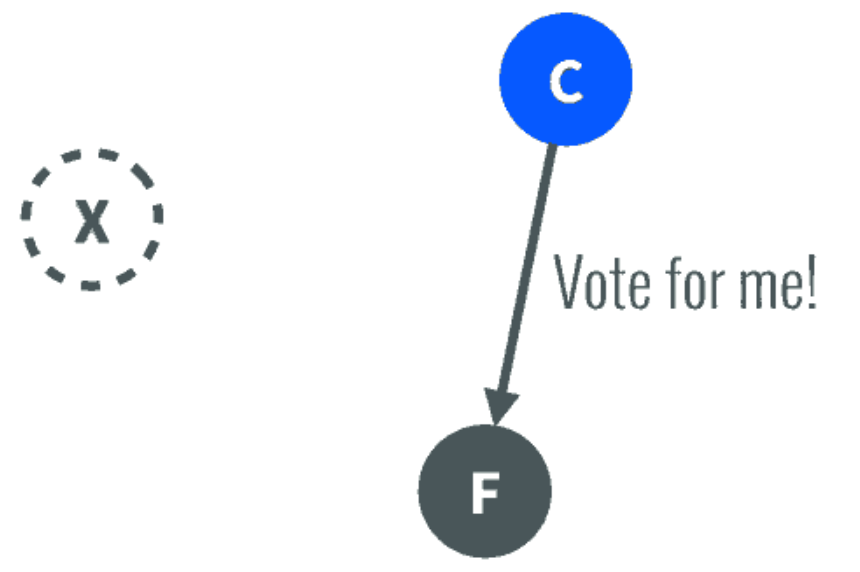
图四 宕机 Follower同意后,其成为Leader,继续承担日志复制等指导工作。
值得注意的是,整个选举过程是有一个时间限制的,如图五:
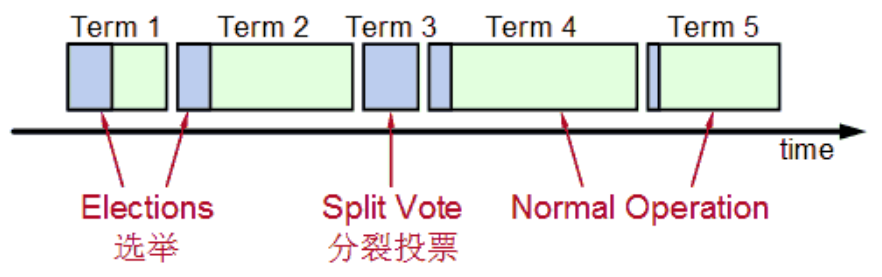
图五 选举
Splite Vote是因为如果同时有两个候选人向大家邀票,这时通过类似加时赛来解决,两个候选者在一段timeout比如300ms互相不服气的等待以后,因为双方得到的票数是一样的,一半对一半,那么在300ms以后,再由这两个候选者发出邀票,这时同时的概率大大降低,那么首先发出邀票的的候选者得到了大多数同意,成为领导者Leader,而另外一个候选者后来发出邀票时,那些Follower选民已经投票给第一个候选者,不能再投票给它,它就成为落选者了,最后这个落选者也成为普通Follower一员了。