
基于Raft协议的NoSQL数据库的设计和实现-Architecture
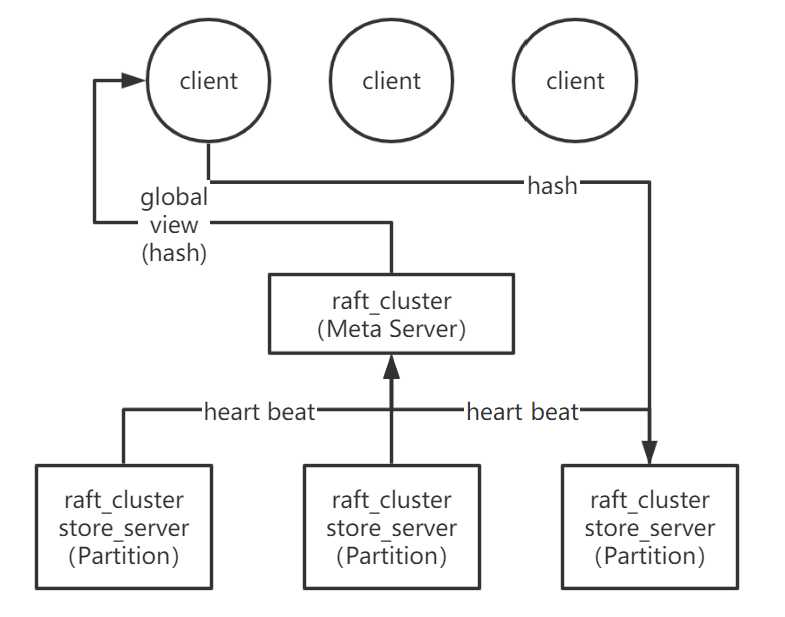
DistKV有着独特的架构,这使得它在一致性方面的能力尤其出色。如图一
1. Store Server
在DistKV中,将存储的数据分为无数可横向扩展的Partition,每组Partitation内部都保留着与其他Partition不同的数据。因为每个Partition都保存着唯一的一份数据,因此需要一些容灾策略来保证数据的可用性。我们采用一组Raft集群来做到这点,每当有DML来修改此分片的数据状态时,Raft将会把操作同步执行到每一个机器上。
1.1 数据模型
因为DistKV是KV数据库,我们采用Map作为我们的底层数据结构。并且考虑到后期会增加range查询的功能,我们使用跳表作为Map的实现方式。
1.1.1 跳表
跳表全称为跳跃列表,它允许快速查询,插入和删除一个有序连续元素的数据链表。跳跃列表的平均查找和插入时间复杂度都是O(logn)。快速查询是通过维护一个多层次的链表,且每一层链表中的元素是前一层链表元素的子集(见图二)。一开始时,算法在最稀疏的层次进行搜索,直至需要查找的元素在该层两个相邻的元素中间。这时,算法将跳转到下一个层次,重复刚才的搜索,直到找到需要查找的元素为止。

这种结构有几个特点是Distkv最需要的:
- 全局有序,这对于Range来说是非常必要的。
- 时间开销小,对于内存式数据库来说,效率是非常关键的。
1.2 多线程模型
1.2.1 历史
一开始Store Server采用多线程+读写锁的方式来保证读写的正常和数据的一致性,但很快我们就遇到了读写性能上的瓶颈。主要原因就是多线程对锁的争抢,Map只有一个,每一次读写就需要获得锁。因此我们采用了一种和RPC多线程结合的方式,来解决以下两个问题:
- 对于key的存取会存在竞争
- 线程等待导致延时过高
1.2.2 多线程模型
最终我们采用异步RPC Server + 无锁队列实现高性能线程安全的store。本方案依赖异步rpc server的能力,且整个过程是没有资源竞争的,也就是不需要对MAP的读取加任何锁。
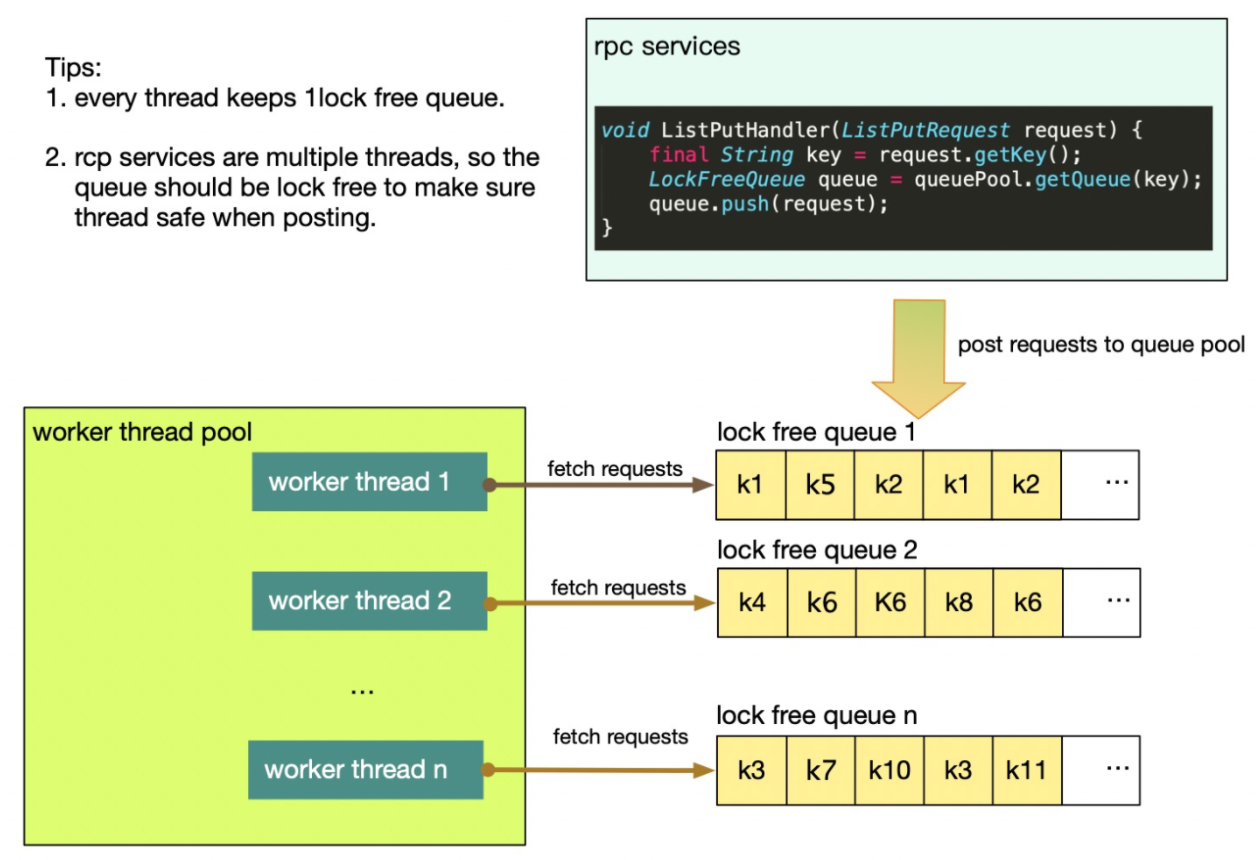
设计n个工作线程,每个工作线程拥有一个与之对应的queue和一个SkipListMap,每个独立的存取线程和内部保存的数据被我们称之为Shard。rpc services会将请求post到不同的queue中,然后worker thread会从queue中fetch request来执行(类似于生产者消费者)。rpc services根据一些策略来决定将request投递到哪个queue中,但不管怎样必须保证,对于同一个key的所有requests,必须投递到同一个queue中,也就是我们保证同一个key的所有requests必须在同一个线程执行,这样就不会有任何的race condition。
当worker thread拿到一个request时,他会解析request并且做对应的执行,执行完之后,需要产生结果给io thread进行返回。
2. Meta Server
因为存在许多分片和集群,那如何集中式的管理这些分片和每一个节点就成为了一个难题。我们将管理分片,订阅,发布,监控节点的功能作为一个独立的运行时组件抽离了出来。
从技术角度讲,Meta Server需要解决以下几个问题:
- DistKV Store Process即时向Meta Server注册,Meta Server监控DistKV Store Process的状态。
- 为每一个注册到Meta Server的DistKV Store process中的shard分配一个partitionID, nodeID, 和shardID。通过检测 DistKV Store process 的健康状况来判断shard存亡,并即时更新路由表。
- 当Dist Store进程挂掉要即时更新路由表,并且将载有挂掉的Dist Store进程数据的Dist Store进程的路由表和原路由表合并或更新。
- DistKV Client首先从Meta Server获取全局路由表, 然后用户提供shardID来获取DistKV Store process的location的服务。(Client利用cache优化这个过程)
- 使用Raft来保证持有数据和服务的可用性
从实现层面,我们采用蚂蚁集团开源的SOFA-JRAFT来作为集群同步时的Raft算法的实现组件。